Markdown编辑器实现原理
Markdown编辑器实现原理
- Markdown简单回顾
- Markdown实现原理
Markdown简单回顾
Markdown实际上是一种轻量级的标记语言。
作为一门标记语言,Markdown 里面自然也会提供各种各样的标记:
- 标题:通过
#来创建 - 强调:通过
**或者__来创建 - 斜体:通过
*或者_来创建 - 链接
- 图片
- 代码
- ....
关于 Markdown 更加详尽的语法,你可以参阅:https://www.markdownguide.org/basic-syntax/
Markdown 最早出现在 2004 年,它的发明者是一个叫做 John Gruber 的人

在 Markdown 出现之前,人们要进行文档编辑,要么使用富文本编辑器,要么使用 HTML,但是这两种方式或多或少有一些缺陷:
- 富文本编辑器:最常见的就是 Word,像 Word 这种富文本编辑器提供了一个所见即所得(WYSIWYG),但是这些编辑器生成的通常是特定格式的二进制文件,并非纯文本,意味着你要打开这些文件还是必须要用对应的富文本编辑器来打开。
- HTML:本身就是用来创建网页,里面所提供的标记语法对于非技术人员来讲,是比较复杂的,并且可阅读性不强。
Markdown 的出现为我们的纯文本编辑带来了一种新的可能性:
- 易读易写
- 可扩展
- 版本控制友好
Markdown实现原理
用户所书写的 Markdown 文本,最终是要被转换为 HTML 格式的。
编译相关的基础知识
什么是编译 ?
所谓编译(Compile),就是将一种语言 A 翻译成另外一种语言 B,其中语言 A,我们称之为源代码(Source code),语言 B 我们称之为目标代码(target code)。
编译的工作是由编译器来做,编译器本质上就是一段程序,或者你可以理解为一个函数:
function compile(text) {
// ...
return text2;
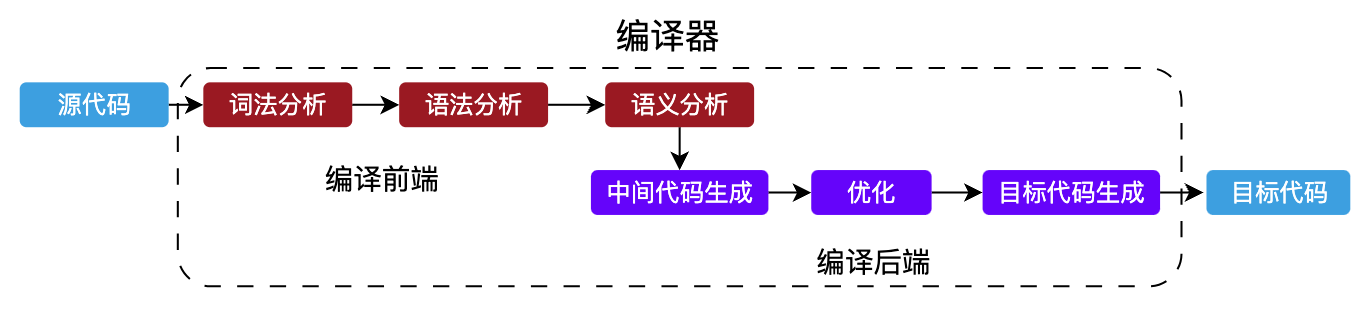
}完整的编译过程,通常包含这么几个部分:
- 词法分析
词法分析是编译过程中的第一个阶段,它的任务就是将源码转换为一系列的词法单元(Token)
所谓词法单元,指的是最小的不可再拆分的单元:关键字、标识符、操作符、数字、字符串
例如:
int x = 10 + 5;经过词法分析,就会将上面源码中的 token 拆解出来:
int(关键字)
x(标识符)
=(操作符)
10(数字)
+(操作符)
5(数字)
;(分号)- 语法分析
这一个步骤主要就是根据上一步所得到的 token 形成一颗抽象语法树(Abstract Syntax Tree,AST)
AST 是一个树形结构,会将比较重要的 token 包含到树结构里面,会忽略不太重要的部分。
例如根据上面的代码,所形成的抽象语法树如下:
Declaration
|
+-- Type: int
|
+-- Identifier: x
|
+-- Assignment
|
+-- Addition
|
+-- Number: 10
|
+-- Number: 5- 语义分析
这个阶段会去检查程序是否符合语法规则,确保你的程序在执行的时候,有一个良好的行为。
int x = "hello";像上面所举例子的错误,就是在语义分析阶段被检查出来。
- 中间代码生成
根据 AST 先生成一遍中间的代码
- 优化
- 目标代码生成
注意,从大的方面去分类的话,还可以分为两大类:
- 编译前端(词法分析、语法分析、语义分析):通常是和目标平台无关的,仅仅负责分析源代码
- 编译后端(中间代码生成、优化、目标代码生成):通常就和你的目标平台有关系
AST
AST 英语全称 Abstract Syntax Tree,翻译成中文叫做“抽象语法树”。
咱们这里可以采用分词的方式来理解它:抽象、语法、树
树其实是数据结构里面的一种,用于表示某一个集合的层次关系,每个节点都有一个父节点和零个或者多个子节点。
A
/ \
B C
/ \ \
D E F树这种结构在平时做搜索、排序以及想要表示层次关系的时候,是用的比较多的。DOM、路由算法、数据库索引。
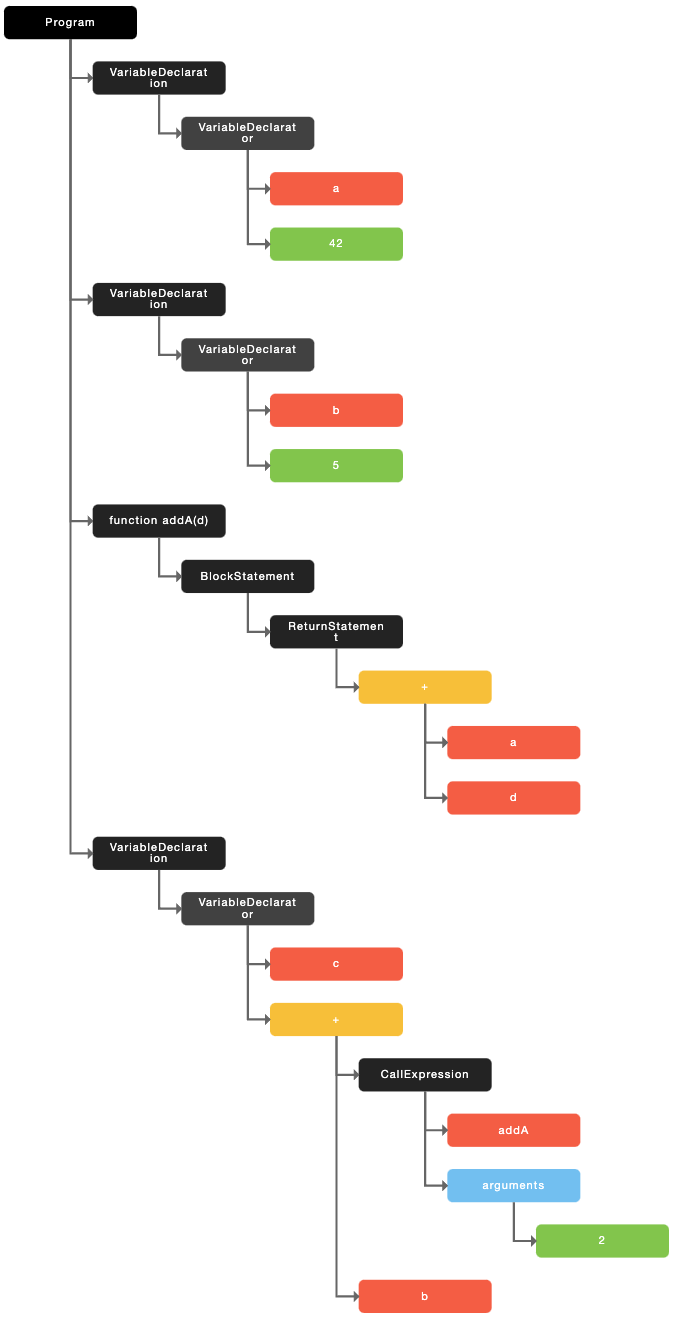
了解了什么是树之后,那么语法树的概念也就比较好理解,比如我们平时所写的代码:
var a = 42;
var b = 5;
function addA(d) {
return a + d;
}
var c = addA(2) + b;对于 JS 引擎来讲,上面的代码实际上就是一串字符串:
"var a = 42;var b = 5;function addA(d){return a + d;}var c = addA(2) + b;";接下来 JS 引擎第一步仍然是分词,将上面的字符串提取成一个一个的 Token
Keyword(var) Identifier(a) Punctuator(=) Numeric(42) Punctuator(;) Keyword(var) Identifier(b) Punctuator(=) Numeric(5) Punctuator(;) Keyword(function) Identifier(addA) Punctuator(() Identifier(d) Punctuator()) Punctuator({) Keyword(return) Identifier(a) Punctuator(+) Identifier(d) Punctuator(;) Punctuator(}) Keyword(var) Identifier(c) Punctuator(=) Identifier(addA) Punctuator(() Numeric(2) Punctuator()) Punctuator(+) Identifier(b) Punctuator(;)接下来根据上面所得到的 token 形成一颗树结构:
最后解释一下为什么要用抽象这个词。
抽象在计算机科学里面是一个非常重要的概念。
这里所指的抽象和现实生活中的抽象是有区别。
- 现实生活:模糊、含糊不清、难以理解
- 计算机科学:将关键部分抽取出来,忽略不必要的细节
我们在将 token 形成树结构的时候,只会关心诸如关键字、标识符、运算符这一类关键的信息,会忽略诸如空格、换行符这一类非关键信息。因此叫做抽象语法树。
抽象语法树这个概念非常的重要,但凡是涉及到转换的场景,基本上都是基于抽象语法树来运作
- Typescript
- Babel
- Prettier
- ESLint
- Markdown
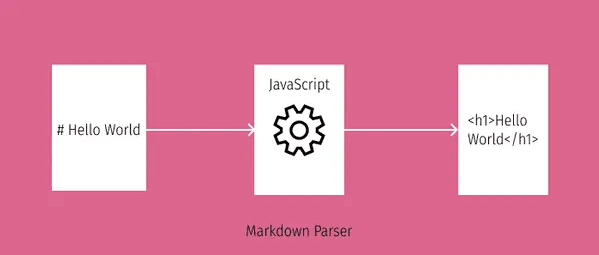
Markdown转换流程
整个 Markdown parser 的执行部分分为三步:
- 词法分析:解析器会对用户的 Markdown 文本进行词法解析,将文本分割成一系列的 token.
- 语法分析:根据上一步所得到的 token,构建抽象语法树。
- 目标代码的生成:解析器遍历 AST,将每个节点转换为相应的 HTML 代码。